
Ncdu 2: Less hungry and more Ziggy
(Published on 2021-07-22)

Ncdu (NCurses Disk Usage) is a terminal-based disk usage analyzer for Linux and other POSIX-y systems, (formerly) written in C and available in the package repositories of most distributions.
Over the past months I have been working on a complete rewrite of ncdu and just released 2.0-beta1. Ncdu 2 is a full replacement of ncdu 1.x, keeping all the same features, the same UI, keybindings and command-line flags, all to make it a proper drop-in replacement. There is, after all, nothing more annoying than having to get re-acquainted with every piece of software you’ve installed every time you decide to update.
Why rewrite, then?
Of course, there wouldn’t really be a point in rewriting ncdu if the new version doesn’t improve at least something. This rewrite is, in fact, the result of me agonizing for a long time about several major shortcoming of ncdu 1.x:
- It has always been a bit of a memory hog. Part of this is inherent to what it does: analyzing a full directory tree and making it smoothly browsable requires keeping track of every node in that tree, and with large directories containing millions of files… yeah, that’ll require some memory. I had, of course, already implemented all the low-hanging fruit to ensure that ncdu wasn’t overly inefficient with memory, but there was certainly room for improvements.
- Ncdu 1.x does not handle hard link counting very efficiently and can
in some (fortunately rare) cases get stuck in an
O(n²)loop. This one is particularly nasty to fix without increasing memory use. - Another hard link-related problem: hard links are counted only once in a directory’s cumulative size, as is consistent with what most other hard link-supporting disk usage analyzers do. This is useful, since a file that has been “duplicated” by means of hard links only really occurs on disk once, the file’s data is not actually duplicated. But at the same time this feature can be misleading: deleting a directory does not necessarily reclaim as much disk space as was indicated by ncdu, since it’s possible for hard links outside of that directory to point to the same file data, and hence for that data to remain on disk. I’ve had a good idea on how to better present such scenarios, but an efficient implementation always eluded me.
None of the above issues are easy, or even possible, to solve within the data model of ncdu 1.x, so major changes to the core data model were necessary. Since each and every aspect of ncdu - both the UI and all algorithms - are strongly tied to the data model, this effectively comes down to a full rewrite. It was during a hike through the local forests that I finally came to a promising solution that addresses all three points.
But first: an apology
I’m sorry. I was anxious to try out that “promising solution” of mine and C isn’t the kind of language that makes quick prototyping very easy or pleasurable. So I ended up prototyping with Zig instead and it ended up being more than just a prototype.
Zig is an excellent programming language and uniquely well suited for little tools like ncdu, but it currently has a major flaw: It’s not even close to stable. There’s no stable version of the language, the standard library nor of the compiler, and each new release comes with major breakage left and right. It also has a fair amount of (known) bugs and its portability story, while impressive for the stage the language is in, is not yet on par with C. The language is looking very promising and I have no doubt that Zig will eventually reach the level of stability and portability to make it a good target for ncdu. But, judging from an outsider’s perspective, that’s likely to take a few more years. And that’s okay, after all, every language needs time to mature.
But what does that mean for ncdu? For regular users, probably not
that much. I provide static binaries for Linux as I’ve always done, so
you can just grab those and run the fancy new ncdu as usual. If you want
to compile from source, you only need to grab the right Zig version and
run zig build. Assuming you don’t run into bugs, that is,
but for the most part things tend to work just fine out of the box. For
distributions, the Zig situation is rather more problematic, primarily
because the version of ncdu is now strongly tied to the version of Zig,
which in turn means that distributions are unable to upgrade these
packages independently from each other. If they package Zig 0.8, then
they may also have to package a version of ncdu that can be compiled
with Zig 0.8. If they want to upgrade to a newer version of Zig, they
may not be able to do so without waiting for me to release a new version
that works with that particular Zig, or maintain their own local patches
for ncdu. The alternative is that distributions will have to support
multiple versions of Zig at the same time, but few have the time and
infrastructure to do that. Either solution is messy, and for that I
apologize.
Considering the above, I will continue to maintain the C version of ncdu for as long as there are people who use it. Maintenance meaning pretty much what I’ve been doing for the past few years: not particularly active in terms of development, just occasional improvements and fixes here and there. I may also backport some additions from future 2.x versions back into the C version, especially with regards to visible interfaces (CLI flags, keybindings, UI, etc), to dampen the inevitable agony that arises when switching between systems that happen to have different versions installed, but features that seem like a pain to implement in the 1.x codebase will likely remain exclusive to the Zig version.
As long as there is no stable version of Zig yet, I will try to keep ncdu 2.x current with the Zig version that most distributions have packages for, which in practice generally means the latest tagged release.
On the upside, ncdu 2.0 only requires the Zig compiler (plus the standard library that comes with it) and ncurses. There’s no other external dependencies and none of that vendoring, bundling and insane package management stuff that haunts projects written in other fancy new languages.1
Less hungry
Ncdu 2 uses less than half the memory in common scenarios, but may in some cases use more memory if there are a lot of hard links. Quick comparison against a few real-world directories:
| Test | #files | ncdu 1.16 | ncdu 2.0-beta1 |
|---|---|---|---|
| -x / | 3,8 M | 429 M | 162 M |
| -ex / | ~ | 501 M | 230 M |
| backup dir | 38.9 M | 3,969 M | 1,686 M |
| backup dir -e | ~ | 4,985 M | 2,370 M |
| many hard links | 1.3 M | 155 M | 194 M |
I have to put a disclaimer here that both my desktop’s root filesystem and my backups play into the strengths of ncdu 2.0: relatively many files per directory and, with ~10 bytes on average, fairly short file names. Nonetheless, you should still see significant improvements if your directory tree follows a different distribution. The big exception here is when you have a lot of hard links. The “many hard links” directory I tested above represents a hard link-based incremental backup of ~43k files, “duplicated” 30 times.
The reason for these differences in memory use are clear when you look at how many bytes are needed to represent each node in the tree:
| ncdu 1.16 | ncdu 2.0-beta1 | |
|---|---|---|
| Regular file | 78 | 25 |
| Directory | 78 | 56 |
| Hardlink | 78 + 8 per unique dev+ino | 36 + 20 per ino*directory combination |
(These numbers assume 64-bit pointers and exclude storage for file names and overhead from memory allocation and hash tables. Extended mode (-e) uses an extra 18 bytes per node in both versions, and both versions use the same memory allocation strategy for the file names.)
While there is room for improvements in the hard link situation, the performance issue in ncdu 1.x that I mentioned earlier isn’t really fixable without a memory increase. I’ve always been cautious with accepting an option to disable hard link detection altogether as the results may not be very useful, but maybe I’ll reconsider that for a future release. A directory that can’t be analyzed at all because you’ve ran out of memory isn’t very useful, either.
Update: Version 2.0-beta2 implements a much more memory-efficient hard link counting algorithm that, combined with the other efficiency gains, should ensure that ncdu 2.0 never uses more memory than 1.x. The memory usage of the “many hard links” directory above has been reduced to 106M in that version.
Another difference that is worth mentioning: when refreshing a directory from within the browser, ncdu 1.x will allocate a fresh structure for the new tree and then, after the scan is complete, free the old structure. This may cause ncdu 1.x to temporarily use twice as much memory if you refresh the top-most directory. Ncdu 2.0 instead does an in-place update of the existing in-memory tree and thereby avoids this duplication. On the other hand, ncdu 2.0 is (currently) unable to re-use tree nodes that have been renamed or deleted, so frequently refreshing a directory that has many renames or deletions will increase memory use over time. I don’t think this is a very common scenario, but should it become a problem, it can be fixed.
Shared links
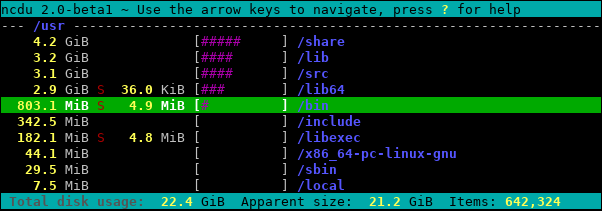
As I mentioned in the introduction, counting hard links can be very confusing because they cause data to be shared between directories. So rather than try and display a directory’s cumulative size a single number, these cases are better represented by a separate column. Here’s what that looks like in ncdu 2.0:
Amount of data shared between directories in /usr:
And the amount of unique data in each incremental backup2:
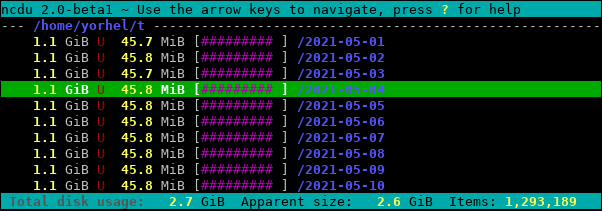
To my knowledge, no other disk usage analyzer has this feature (but please do correct me if I’m wrong!)
You can, for the time being, switch between the two views by pressing ‘u’. But if I keep assigning keys to each new feature I may be running out of available keys rather soon, so maybe I’ll reclaim that key before the stable 2.0 release and implement a quick-configuration menu instead.
This feature does come with a large disclaimer: the displayed shared/unique sizes will be incorrect if the link count for a particular file changes during a scan, or if a directory refresh or deletion causes the cached link counts to change. The only way to get correct sizes when this happens is to quit ncdu and start a new scan, refreshing from the browser isn’t going to fix it. There is currently no indicator or warning when this happens, that’ll need to be fixed before I do a stable release.
Other changes
There’s a bunch of other changes in ncdu 2 that came naturally as part of the rewrite. Some changes are good, others perhaps less so.
The good:
- Improved handling of Unicode filenames. It still doesn’t handle Unicode combining marks, but at least it can now recognize full-width characters and it won’t cut off filenames in the middle of a UTF-8 sequence.
- Improved performance when using
--exclude-kernfsthanks to caching the result ofstatfs()calls. I tried to measure it and only noticed a ~2% improvement at best, but it’s something. - In the ‘Links’ tab in the info window for hard links, it is now possible to jump directly to the selected path.
- The file browser now does a better job at remembering the position of the selected item on your screen when switching directories.
The ambiguous:
- Ncdu 2.0 doesn’t work well with non-UTF-8 locales anymore, but I don’t expect this to be a problem nowadays. It can still deal with non-UTF-8 filenames just fine, but these will be escaped before output rather than directly thrown at your terminal as ncdu 1.x does.
- The item information window organization is a little bit different. Just a tiny little bit, I promise.
- Ncdu 2 now uses the
openat()family of system calls to scan directories. This is generally an improvement over thechdir()andopendir()approach of ncdu 1.x, but does require a few more file descriptors (big deal) and is less portable to ancient systems (would Zig even work on those?).
The less good:
- Opening the ‘Links’ tab in the info window for hard links now requires a scan through the in-memory tree, so it’s noticeably slower. To my surprise, though, a full scan through a tree with 30+ million files takes less than a second on my system, so in practice this probably isn’t going to be a problem (and who uses that ‘Links’ tab, anyway?).
- Refreshing a directory may leak memory (as discussed earlier).
- The browser UI is not visible anymore when refreshing or deleting a directory. The problem is that the browser keeps cached information about the opened directory, and this cache may be invalidated while the refresh/deletion is running. This is also kind-of a problem in ncdu 1.x, but it’s less pronounced. There have been requests for allowing interactive browsing while ncdu is still scanning, so this won’t a problem if I ever get around to implementing that, but it’s not much of a priority on my end. Updating the browser’s cache on each UI draw is going to be too expensive, so I’m not yet sure how to handle it.
- Lots of new bugs, no doubt.
Next steps
Grab yourself an ncdu-2.0-beta1 and test! The source code is available in the ‘zig’ branch in the repository.
My first priority is to get 2.0 ready for a “stable” release, which means it needs to get some serious testing in the wild to evaluate how well it works and to flesh out the inevitable bugs. It’s still a bit unclear to me if it even makes sense to release a stable version when the foundation it’s built on is inherently unstable, but let’s just see how things go.
On the slightly longer term, the rewrite to Zig opened up the possibility for a few more features that I’ve been wanting to see for a while, but that seemed tricky to implement in 1.x.
- Multithreaded scanning. This will be useless for old fashioned rotating hard drives, but for SSDs and especially NVMe, scanning performance can be greatly improved by distributing the work across multiple threads. While rewriting the code I came up with a promising idea on how to implement this, so I’d love to experiment with that in future versions (io_uring is also an interesting target, but potentially even more complex).
- Faster
--exclude-patternmatching. Honestly, this feature is currently so slow in both versions that I’m surprised nobody has ever complained about it (not to me, in any case). It’s possible to slow ncdu’s scanning performance down to a crawl with just a few patterns, a more clever matching implementation could provide major improvements. - Exporting an in-memory tree to a file. Ncdu already has export/import options, but exporting requires a separate command invocation - it’s not currently possible to write an export while you’re in the directory browser. The new data model could support this feature, but I’m still unsure how to make it available in the UI.
- Transparent export compression. The export function dumps
uncompressed JSON data and is designed to be piped through
gzipor similar commands. While this is documented in the manual page, I still see many people writing the export to disk without any sort of compression. That’s a pretty big waste of space, so it would be nice if ncdu could transparently run the exported data through external (de)compression tools to make this easier and more discoverable.
These features are in addition to a long list of other possible improvements that I’ve been meaning to work on for the past decade, so don’t expect too much. :)
That’s not to say Zig is immune to the problem of projects using hundreds of tiny little dependencies, but that development style isn’t strongly encouraged in its current state: the standard library already covers a lot of ground, package management solutions are still being worked on and it’s easy enough to just use existing C libraries instead.↩︎
I would absolutely love for directory-level reports like these to be available for other forms of data sharing, such as reflinks or btrfs/ZFS snapshots. But alas, I doubt I’ll ever be able to implement that in ncdu. Even if I could somehow grab and untangle the underlying data, keeping track of every block in a large filesystem is no doubt going to be very costly in both CPU and memory. I did write a little tool some time ago to generate such reports for quota-enabled btrfs subvolumes, but I ended up disabling the quota feature later on because even that is pretty costly. There’s also btdu, which takes a very interesting approach to analyze btrfs filesystems.↩︎